About
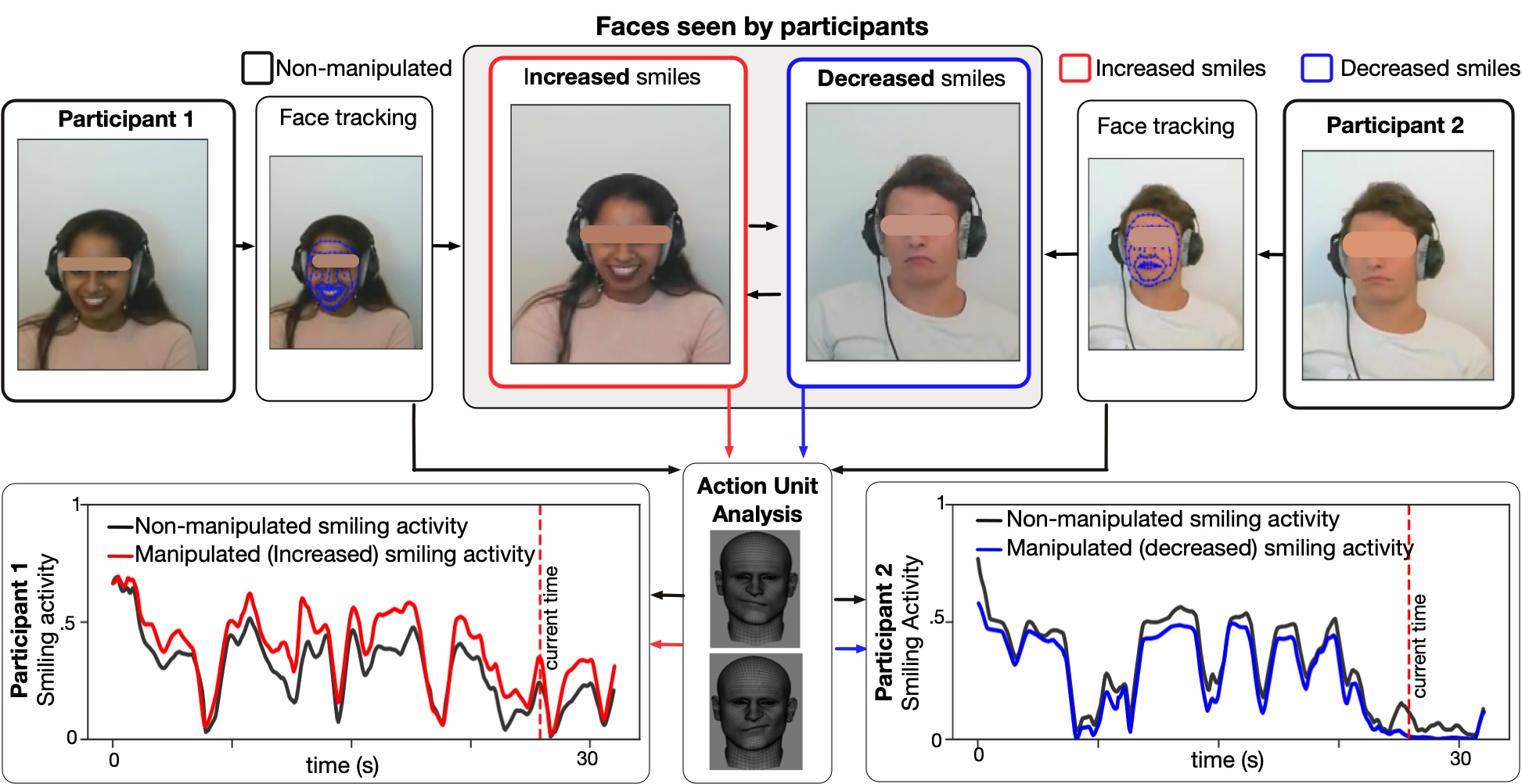
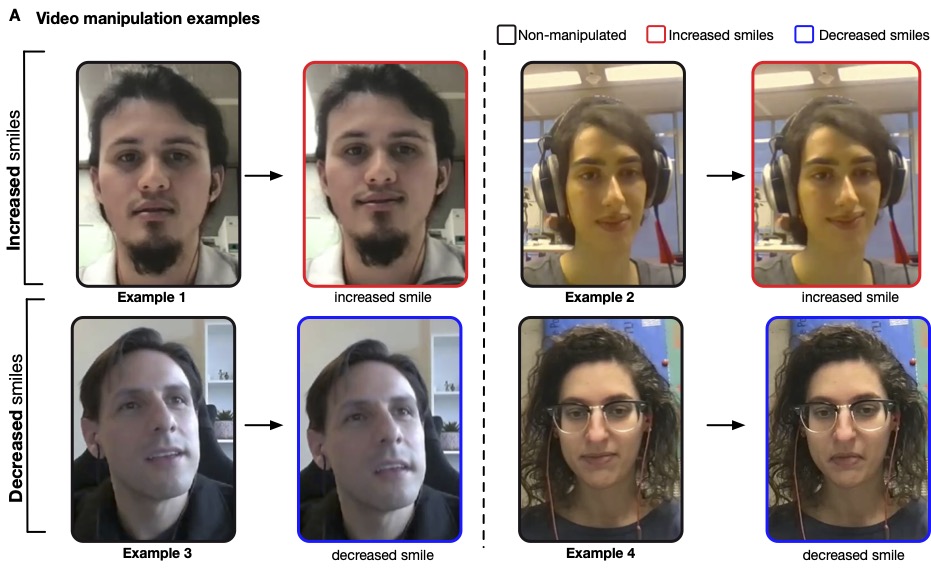
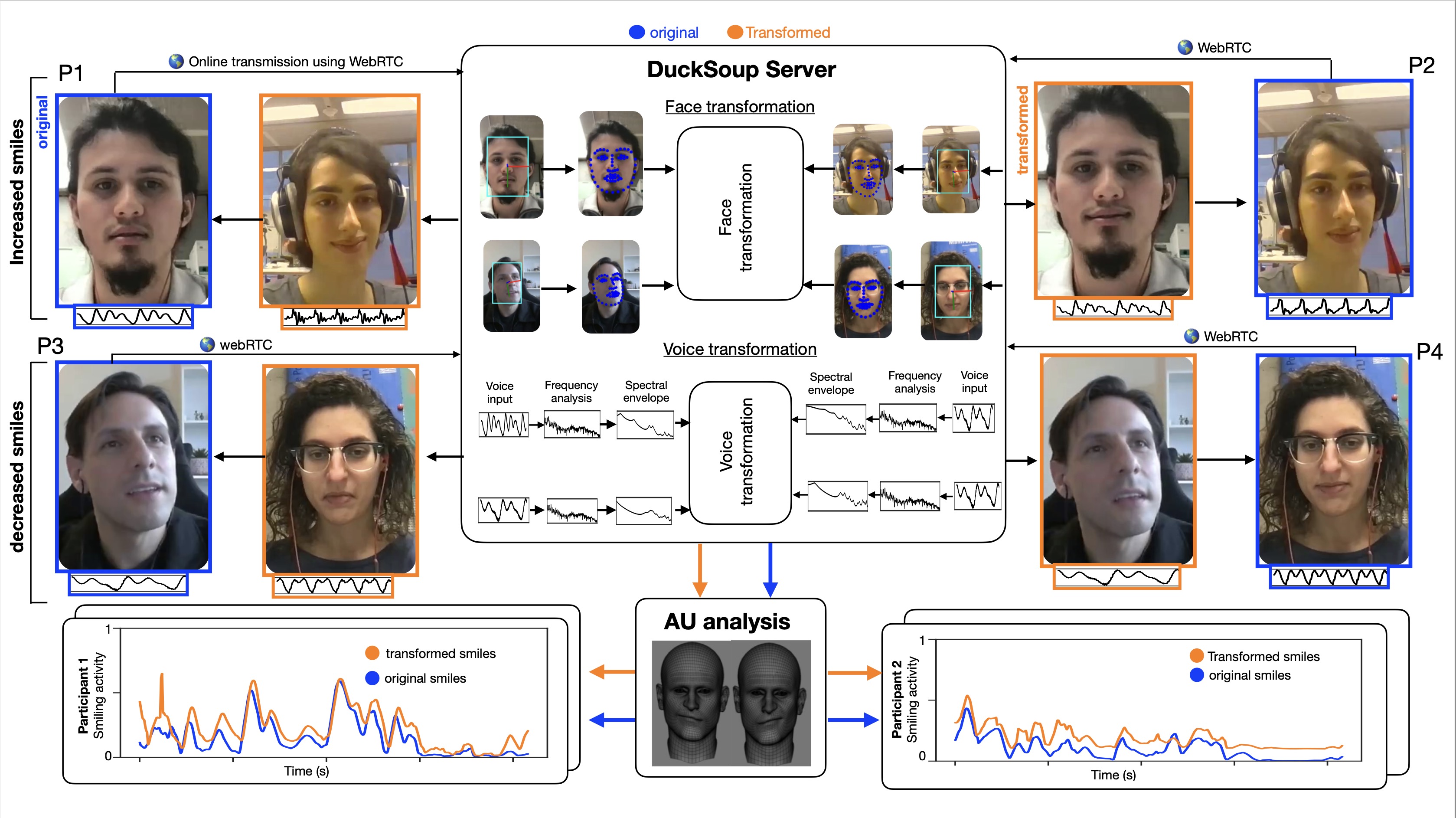
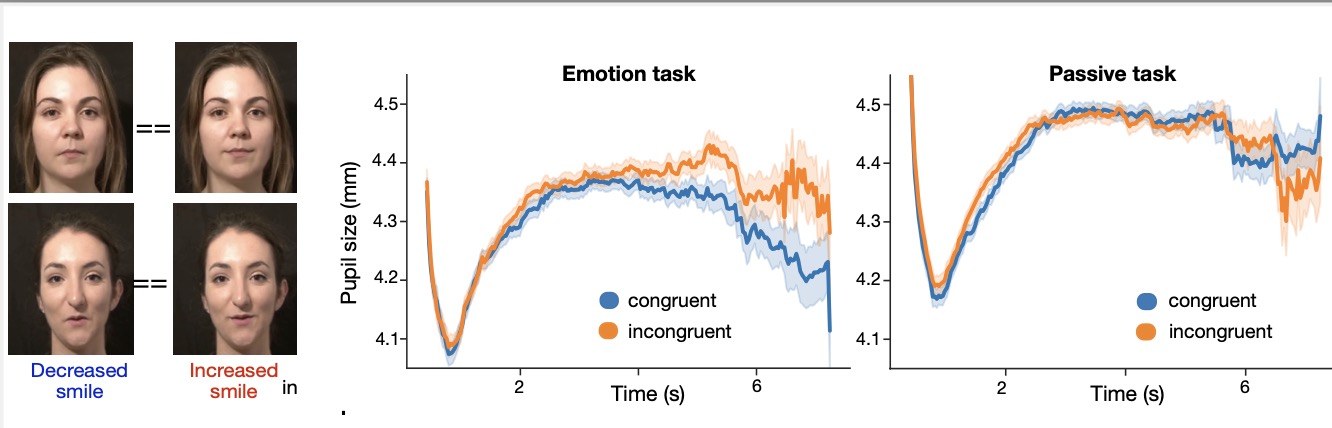
 Hi! I'm Pablo Arias-Sarah, a French/Colombian researcher working in the French National Center for Scientific Research (CNRS), in the Psychology and Neurocognition Lab in the Université Grenoble Alpes in France. I study human social interactions using real time voice/face transformations. To do this, we developed a videoconference experimental platform called DuckSoup, which enables researchers to transform participants' voice and face (e.g. increase participants' smiles or their vocal intonations) in real time during free social interactions. I am interested in human social communication, social biases and human enhancement.
Hi! I'm Pablo Arias-Sarah, a French/Colombian researcher working in the French National Center for Scientific Research (CNRS), in the Psychology and Neurocognition Lab in the Université Grenoble Alpes in France. I study human social interactions using real time voice/face transformations. To do this, we developed a videoconference experimental platform called DuckSoup, which enables researchers to transform participants' voice and face (e.g. increase participants' smiles or their vocal intonations) in real time during free social interactions. I am interested in human social communication, social biases and human enhancement.
I hold a PhD in cognitive science from Sorbonne University (Paris, France), a Master of Engineering in digital technologies and multimedia from Polytech' Nantes (Nantes, France), and a Master of Science in acoustics, signal processing and computer science applied to sound, from IRCAM (Paris, France). I also worked in Lund University (postdoctoral research) and Glasgow University (Lecturer and Marie Curie Fellow ). You can find a complete list of my publications here or follow me on Bluesky to keep up to date with my latest work.